Context
I spend most of my time building Promptfoo, an open-source LLM evaluation tool. I was an avid Cursor user before experimenting with Claude Code earlier in 2025, but usage picked up significantly in July. By the end of that month I was spending close to $10K in API credits, just on interactive development work, not production traffic.
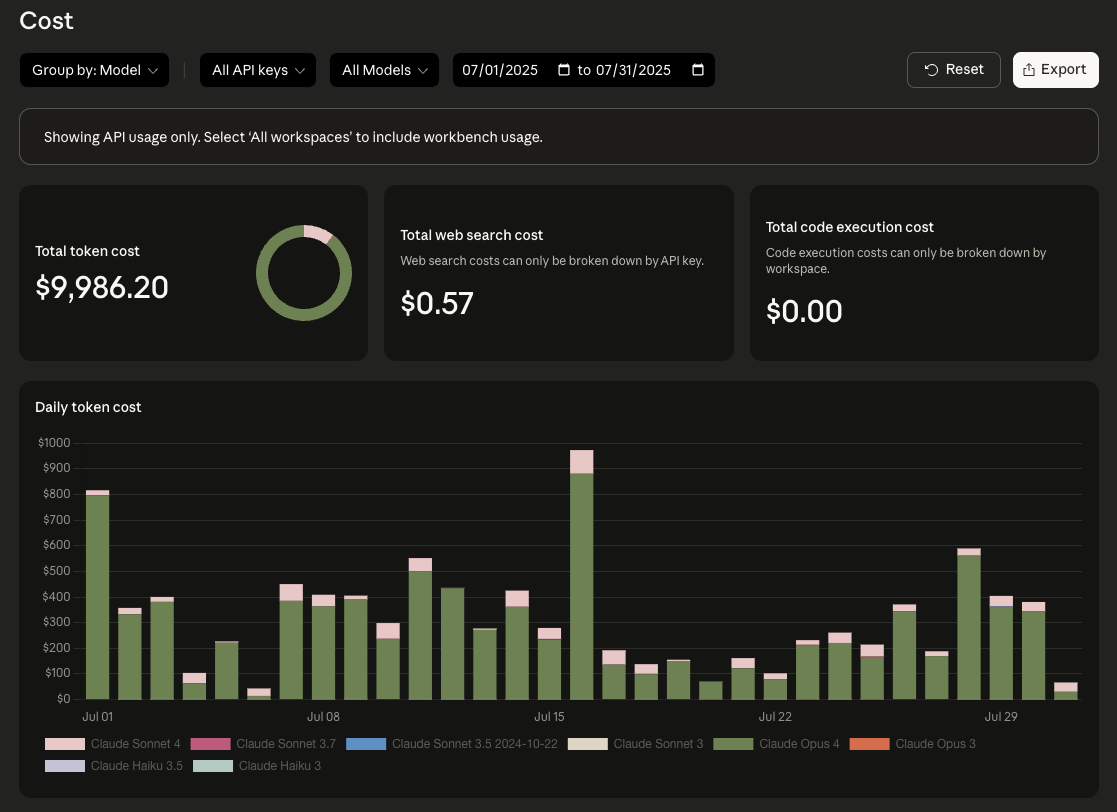
Anthropic gave us a generous credit grant for Promptfoo, so this didn't actually cost us anything, but I'm grateful for their support. At that usage volume, switching to a Max subscription made sense. I now run two Max subscriptions because I hit the weekly usage limits on a single account.
Over the course of 2025, I've merged 1,000+ PRs to Promptfoo using this approach. What follows are notes on what I've learned about making parallel agents work in practice.
My setup
Here's what I'm currently running:
- Two Max subscriptions. I hit weekly limits on one account when I'm running multiple long sessions, so I rotate between two accounts. At my usage, Max pricing is materially cheaper than paying API rates for interactive dev.
- Ghostty with six panes + notifications. Four panes are independent working copies of the same repo (git worktrees), plus two panes for other projects. I rely on Ghostty's bell/attention notifications as a scheduler: when a pane "dings," I either merge the diff or push it back with one follow-up.
- Four parallel worktrees. Each task gets its own worktree so sessions don't collide, and I can review diffs in isolation.
- Opus 4.5 as my configured default. Claude Code defaults to Sonnet 4.5, but I run Opus 4.5 as my personal default for this workflow because I care more about correctness than latency, and I'm usually running several sessions anyway.
- Plan-first workflow. For non-trivial tasks I start in Plan Mode, write the plan to a file, review it, then switch to implementation. More on this below.
- Cross-model verification. I use the Codex CLI and Gemini CLI for second opinions. I also occasionally run isolated throwaway repros in separate environments to test edge cases without touching the main codebase.
The throughput gain comes from concurrency plus verifiers, not prompt tricks.
The workflow
- Start in Plan Mode for anything non-trivial
- Write the plan to a file in-repo, then review it
- Implement in a dedicated worktree with fast checks (tsc/tests/lint)
- Verify in a clean worktree and in the browser
- Cross-model audit for changes that touch contracts, auth, or security
- Only then: PR + merge
On using --dangerously-skip-permissions
I run Claude Code with the --dangerously-skip-permissions flag on these projects.
This is probably a bad idea. The flag disables all permission prompts for file edits and shell commands, which means Claude can modify any file or run any command without asking. I expect this will eventually cause a problem. But the friction of approving every edit and command (dozens per session) breaks the flow that makes parallel agents useful.
If you want this workflow without the risk, the official recommendation is to run it in an isolated environment (container or similar). Claude Code also offers /sandbox mode for filesystem and network isolation of bash commands, which is safer than bypassing permissions entirely.
For anything unfamiliar, I start in Plan Mode first, then switch to implementation. Claude Code's write boundary is scoped to the directory it's started in, which helps for file edits, but bypassing permission prompts is still "arbitrary commands without human review."
For these specific repositories, with git as a safety net and the ability to quickly review diffs, I've decided the productivity gain is worth the risk. Your situation is probably different.
Verification layers
I've found that models improve significantly when they can verify their own work. Each layer of verification seems to help:
- Type checkers. TypeScript catches type errors immediately. Claude can see the tsc output, adjust, and re-run within the same task.
- Unit tests. Fast, targeted feedback. Claude runs them after changes and can see exactly what broke.
- Linters and formatters. Catch style drift and build failures before they accumulate across files.
- Browser automation. Claude can navigate actual web pages, fill forms, and verify UI behavior. More on this below.
When the agent can run tsc and a fast test suite, it converges in fewer iterations and I see fewer speculative edits. The tighter the feedback loop, the fewer bad guesses make it into the final diff.
Browser automation: --chrome for interaction, Playwright MCP for screenshots
I use native Chrome integration (claude --chrome) for interactive web workflows: reproduce UI bugs, test forms, and inspect console/network output. It's low ceremony and stays inside my normal browser session.
Chrome mode is great for interaction; for deterministic screenshot artifacts I still use Playwright MCP. I want saved files in PRs and issue threads, and Playwright handles that workflow reliably.
Division of labor
These verification layers work because Claude and I have a clear division of labor. The agent finds the right files, makes edits, runs verification tools, navigates browser interfaces, and drafts commits and PR descriptions. I set the goal and constraints, review diffs for correctness and unintended behavior changes, run cross-model audits for important changes, and decide when something is ready to ship. As Simon Willison notes, a computer can never be held accountable. Claude does the implementation work; I own the outcome.
Plan Mode + writing plans to files
For multi-file changes, I start in Plan Mode so the agent does a read-only pass: locate files, read code, and propose steps. You can toggle it with Shift+Tab, or start there with:
claude --permission-mode planWhen the plan looks right, I switch out of Plan Mode and have it write the plan into docs/plans/<task>.md. Then I implement against that file like a checklist.
The plan file also survives context resets and makes it easier to hand a task to a different session later.
Extended thinking and when I use ultrathink
Opus 4.5 has extended thinking enabled by default, but I still use ultrathink explicitly for the cases where I want the agent to slow down: security review, auth changes, and multi-step refactors.
Example:
ultrathink: audit this diff for security issues and behavior changesIn Claude Code, ultrathink is the keyword that allocates a per-request thinking budget. Other phrases like "think hard" read like emphasis, but they don't allocate thinking tokens. This only works as described when MAX_THINKING_TOKENS is not set; if you've set that environment variable, it overrides the per-request ultrathink behavior.
Examples of what this enables
A 7-year-old Winston bug
I was debugging a logging issue in Promptfoo and asked Claude to investigate. Instead of patching our code, it identified a bug in the Winston package that had been there since 2018: logger.end() could emit the finish event before the file write actually completed. You could call logger.end() followed by process.exit() and lose your last few log lines.
Claude asked if I wanted to open a PR upstream. It wouldn't have occurred to me to look there.
The fix involved adding a _final() hook to Winston's File transport so the stream waits for the underlying fs.WriteStream to finish flushing. Claude wrote a minimal reproduction case and regression tests, then opened the PR. The Winston maintainers merged it, and the fix shipped in v3.19.0.
Static analysis and security work
A significant portion of my work involves static analysis. At Promptfoo I've built code scanning and model audit features. I also audit other open-source projects, which has resulted in dozens of disclosed security vulnerabilities.
Claude Code handles much of the mechanical overhead: locating relevant files, tracing data flows through a codebase, drafting fixes, running verification checks. I work with agents to reproduce and verify vulnerabilities.
Volume
Running 6 panes in parallel lets work proceed concurrently: one agent implements a feature while another runs verification; a third reviews diffs or explores edge cases. No waiting, minimal context switching.
In 2025 I merged 1,000+ PRs to Promptfoo:
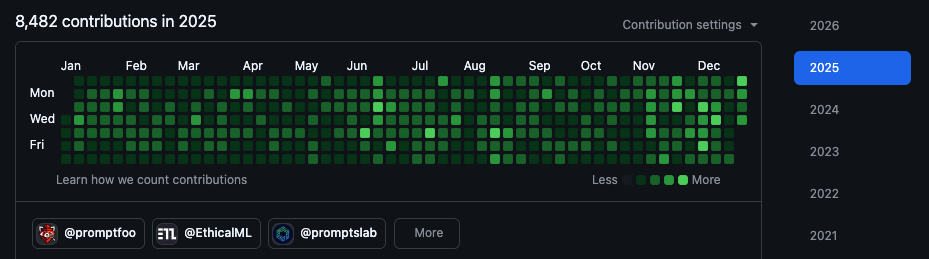
This graph includes commits, PRs, reviews, and issue activity. I'm using it as a rough proxy for output.
For comparison, I had 5,396 contributions in 2024, before these workflows were mature. Same person, different tooling.
Using multiple models for verification
I regularly check Claude's work using other models: running the Codex CLI and Gemini CLI in separate sessions.
Different model families seem to have different blind spots:
- Claude sometimes introduces unnecessary abstractions or adds flexibility that isn't needed
- Codex catches edge cases and type inconsistencies that Claude misses
- Gemini flags structural issues and suggests simpler alternatives
Claude recently refactored an authentication flow and the tests passed. Gemini pointed out that the new code changed the error messages returned to clients, which would break existing error handling in our frontend. Claude's tests hadn't covered that contract.
For substantial changes (large refactors, accessibility improvements, performance work) I run a second agent as a verifier. The task isn't complete until both the implementation and verification pass in a clean worktree.
CLAUDE.md + AGENTS.md
I keep project instructions in CLAUDE.md files (root and relevant subdirectories). Each CLAUDE.md is short and mostly points to an AGENTS.md file with longer, task-specific guidance.
The trick is to make the rules load reliably. Claude Code supports importing files from CLAUDE.md using @path syntax: literal includes, not evaluated inside code spans or fenced blocks. This lets me keep the top-level memory file small while pulling in the detailed playbook when needed. You can use /memory to debug what actually loaded.
I update these files whenever I see the same mistake twice. The goal isn't comprehensive documentation. It's preventing the specific failures that actually happen in this codebase.
Example
The CLAUDE.md at the Promptfoo repo root just contains:
@AGENTS.mdThe AGENTS.md file has the actual rules:
# Promptfoo Development Guide
## Build Commands
- Lint: `npm run lint`
- Type check: `npm run type-check`
- Tests: `npm test`
- Build: `npm run build`
## Critical Rules
- Never edit files in `dist/` - they're generated
- Never modify `package.json` dependencies without asking
- Test files must end in `.test.ts` or `.test.tsx`
- All API endpoints require authentication checksContext rot and compounding mistakes
An agent with the wrong plan rarely gets better. When the initial approach is flawed, more iterations usually make things worse. The agent doubles down on the wrong abstraction, adds complexity to work around problems it created, or quietly changes behavior to make tests pass. I've learned to reset the context and try again instead of pushing through.
Compounding mistakes happen when one session makes an error and another session builds on that work. The second agent inherits the first agent's bad assumptions, and the errors multiply. This is why verification passes are critical before merging anything.
What's changed
The surprising part isn't that I'm shipping more code. It's that I'm shipping better code. The verification loops catch more bugs before they reach production. Cross-model audits surface issues I wouldn't have noticed manually. Fresh-context reviews find the kind of subtle problems that are hard to spot when you just wrote the code yourself.
The lower friction has also changed how I work. I'll fix bugs during customer calls now. I'll keep momentum on small fixes that would have felt too tedious to context-switch into a year ago. The mechanical parts (finding files, running tests, drafting commit messages) have low enough overhead that the work stays focused on the parts that actually need thinking.
What makes this work is the convergence: native browser integration (--chrome), extended thinking (ultrathink), cross-model verification, and tight feedback loops from type checkers and tests. Individually these are useful. Together they change what's practical to build.
Right now, the practical win is straightforward: parallel sessions with fast verifiers and explicit ownership beats single-session prompting.
Links
Official Claude Code docs:
- Claude Code best practices - Anthropic's official guide
- Use Claude Code with Chrome (beta) - Native browser integration
- Common workflows - Git worktrees and parallel sessions
- Model configuration - Switching between Sonnet and Opus
- Manage Claude's memory - CLAUDE.md and .claude/rules
- Claude Code with Max plan - Usage limits and billing
Browser automation:
- Chrome DevTools MCP - MCP server for advanced debugging
- Playwright MCP - Browser automation via MCP
Related:
- Promptfoo - The project where I use this workflow
- Simon Willison on accountability - Who's responsible for AI-generated code
- Boris Cherny on AI-assisted development - Productivity perspectives